疫情数据的可视化和ARIMA预测
简单记录下这些微小的工作。
GitHub Pages
https://hrbinbin.github.io/Covid19predict/
初衷
探索一下,机器学习能否做到
超越检测手段、统计方式的不确定性,对真实情况进行 fit
没见过下降趋势的时候预测下降趋势。这一点的范畴其实在 deep reinforcement learning 里面研究挺多,可惜本场景是否适用还未知
目标是拐点或者趋势
现阶段
- 英国首相今天宣布疫情高峰已经过去,不过从可视化结果来看,确实是“过去”了,但这好转速度也太慢了
- 既然拐点过了,那么情况和数据肯定是越来越好的
- 还有没有继续做,做什么
- 在日程上的有 CNN for time-series 和 LSTM RNN
- 总确诊人数肯定是 S 型曲线。现存确诊这个数据对英国来讲就是没有,治愈数目、重症数目就没怎么更新
- 现阶段预测现存确诊的意义大于预测总确诊的意义;预测的总确诊只能用来展示拐点情况了
- 有很大的冲动想把这个项目 archive 了,因为没有现存确诊的每日数据和历史数据。就留个可视化
数据源 json2csv.R
- Jeff 的 API。用于获取英国历史数据。
- JHU 的全球数据仓库。用于获取欧洲三国数据。
- 韩国数据也源于 JHU,中国大陆数据采用卫健委的数据。英国之外的数据均用于对比英国。
代码没什么好讲的,全部输出 csv。
现状可视化 log_vis.R
一个很重要的点就是用普通的 line plot(y 轴:确诊人数,x 轴:时间)很难对比或者看出一个国家情况的好坏。用对数数轴(log-y /w log-x)也凸显不出来显著差距。这里采用的是 minutephysics 的视频中提到的方法:How To Tell If We’re Beating COVID-19。我也在寻找更优的数据展示方式,有知道的也欢迎告诉我。
这个可视化采用 y 轴每日新增,x 轴总确诊来作图,全对数数轴。上面的是视频已经很到位地展示了它的效果。下面的图片也说明了欧洲三国领先英国的一个抗疫局势。更多对比
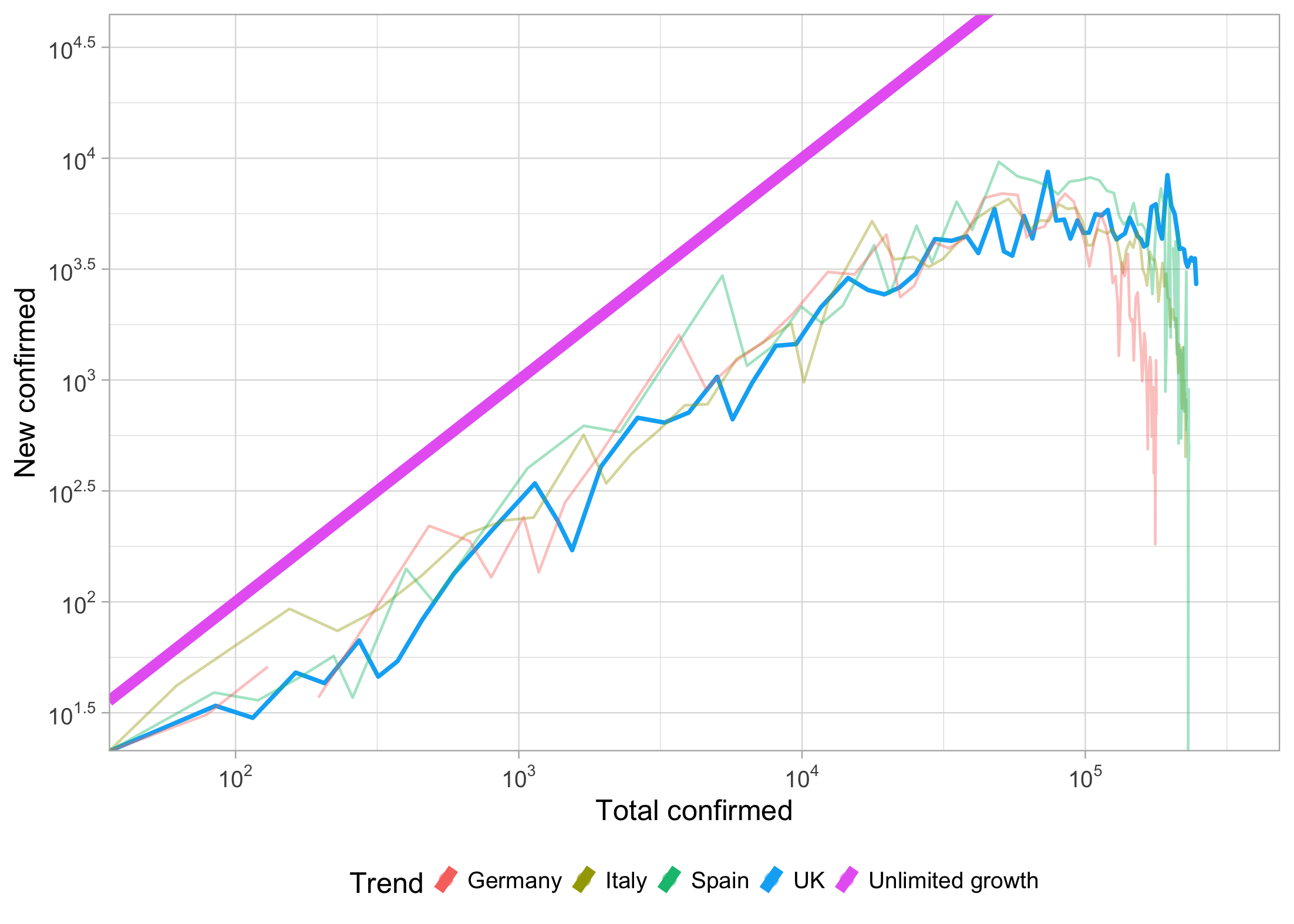
所有可视化都通过ggplot2完成。确实很麻烦很费时间(特别是 legend),但在目前我看来做可视化 ggplot 已经是最优方案了。
对数数轴:
1 | scale_x_log10(limits = c(55,316123), breaks = trans_breaks("log10", function(x) 10^x), labels = trans_format("log10", math_format(10^.x)))+ |
ARIMA movingAverage.R
非季节 ARIMA 就三个参数 (p, d, q)。p 是 AR(自回归)的阶数,描述时间序列的 lag,d 是差分的阶数,这个阶数下的时间序列应该具有平稳(stationary)的趋势。q 是 MA(滑动平均)的阶数,与滑动窗口大小有关。
- d 在本情况下是不会超过 3 的,通过画一下差分后的数据序列就能看出来。最大化 heteroscedasticity 的 d 可能就是 2 了。
- p 和 q 就让它自动去寻找吧,根据实际情况设一下上下界限
- p 和 q 会显著增加模型复杂度,因此存在 AIC(p, q)法则。不过我没有考虑 23333。
后期版本,自动寻优的 ARIMA 模型:
1 | UK.autoARIMA = auto.arima(dfUK$confirmed, |
1 | tsdiag(UK.autoARIMA) |
这里默认的寻参目标是 AIC,可选的目标还有 AICc,BIC 和 likelihood。我并不知道哪个寻参目标更好,所以就用了默认的。
正常情况为了一个更精确的结果,还是应该关闭approximation,打开并行,这样的结果更好,还可以避免 q 很大的时候,AIC 计算直接蹦到 Inf 的问题。当然如上一段落,换个寻参目标可以解决这个问题。
早期版本中,我手动 grid search 寻参,结果 p 和 q 都落在 10+的范围,寻参时间也很长。一个可视化三维或者更高维的 grid search 结果的方法是:
假设变量 a 寻参范围为 d1,变量 b 为 d2,变量 c 为 d3
y 轴为寻参目标(这里是 AIC),x 轴为
c+b*(d3+1)+a*(b*d2+d3+1)这里的 1 可以换成别的正常数来增大间距
关于参数理解:Understand p, d, and q
现阶段的自动寻参结果表明,p 是肯定落在 10 以上的区间的,以 likelihood 为指标甚至会趋向于最复杂的模型(p 会落到寻参上界);q 对模型的影响难以简单描述,还是认真搜一下比较好。
接下来就是构造 data frame 无脑作图了。AIC 可视化出来可能很难理解,这里就做了 residual 的可视化。
不得不说显而易见的,这样的时移统计模型的误差可以做到非常小:**我预测了这么多天,没有一天的误差超过 1%**,一般和当天公布的总确诊数字相差都不会超过 1000 人。
这就让我回到了初衷里面讲的,它都这么精确了,那么它达到我们的目标了吗?做更精确的 CNN、RNN 模型意义大吗?对我们的生活或是决策参考意义大吗?
所以我准备再思考一下这个问题,或许明天写个 1D-CNN 试试看。DNN 能吸收更多的特征,但对这种统计手段/统计方法会很大影响结果的场景,如上讨论,直接预测总确诊意义确实不是很大。
最早的目标是学习相似国家的数据,然后 transfer learning 到英国上面。现在想想,可能 transfer 完就预测一个确诊人数着实没啥用。试试才知道,说不定等几天过去它就变成一个纯可视化的项目了。
目前最有价值的也就是如下两图了(GitHub 的图床,每日更新)。
英国趋势
1 May:确实不大像拐点的样子,尽管首相已经这么承认了。这个拐点是真的平缓,表明英国在收容这一块上做的很艰难。还是要谨防上升趋势。
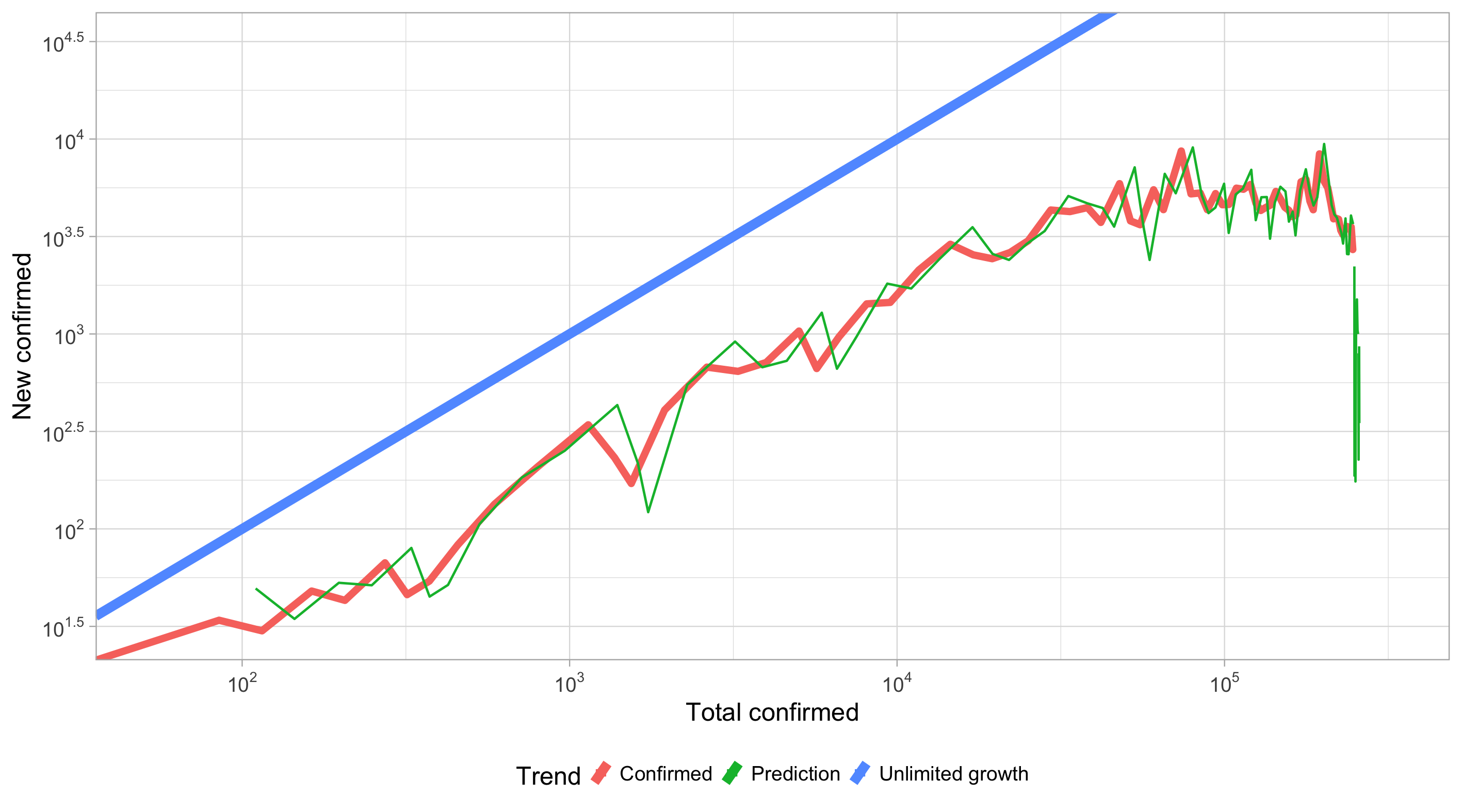
每日新增预测
MA 阶数 q 在快速寻优和高阶 AR 下趋向于选择小的值。更精确的自动寻优结果之后会更新。
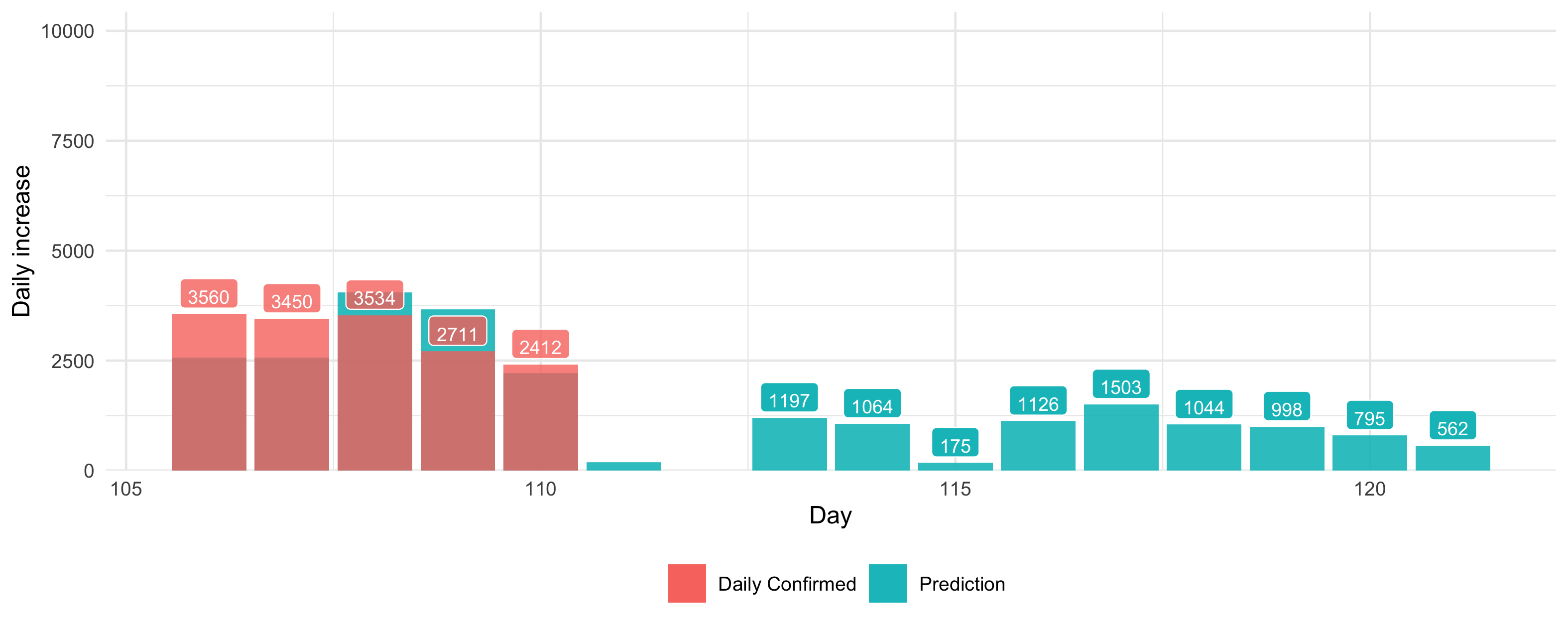
Updates on 21 May
准备结束预测功能。
最早是手动寻参,后来用 autoArima 自动寻参,现在是周期在 7 的倍数里面寻优。
思前想后现实意义不大,考虑到
- 英国这个疫情趋势也没什么变数了
- 增加慢慢放缓,有的开始清零了
- 数据校对很难
- 有突然增加/减少的核对人数